在Unity的Manual中有段对GPU优化的提示:
Some GPUs, particularly ones found in mobile devices, incur a high performance overhead for alpha-testing (or use of the discard and clip operations in pixel shaders). You should replace alpha-test shaders with alpha-blended ones if possible. Where alpha-testing cannot be avoided, you should keep the overall number of visible alpha-tested pixels to a minimum.
意思是说某些类型的GPU设备,尤其是移动设备。在pixel shaders中使用了alpha-testing或者是使用discard和clip操作会导致很高的性能压力,应该使用alpha-blended来代替alpha-testing。
首先这里要明白不管是alpha-testing,clip还是discard都是做了同样的原理的操作。就是针对某一个设定好的条件,根据这个条件满足的正常渲染,不满足的直接舍弃不渲染。举个例子,针对某个渲染对象如果alpha大于0.5时不可见,那么利用discard做如下操作即可:
1 | |
这里的问题是为什么向discard会导致很高性能压力呢?原因还得用图形的渲染架构来解释。现代的图形架构可以归为以下三类:
- Immediate Mode Renderer (IMR)
- Tile Based Renderer (TBR)
- Tile Based Deferred Renderer (TBDR)
IMR
IMR主要是PC平台上使用的GPU的图形渲染架构。采用IMR模式从应用层提交的每个渲染对象都会经过Pipleline的每个阶段,这个过程渲染管线(pipleline)不会中断,渲染的速度快。而且GPU是很多单元并行操作,每个单元只要负责渲染自己部分的数据即可,在处理fragment shader之后只需要各个单元做一遍排序即可。整个过程如下:
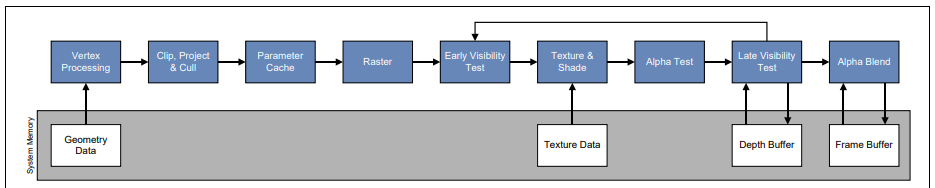
传统的IMR会造成处理很多无效的渲染对象。现在比如先处理了一个游艇,但是随即需要在这个游艇的正前方渲染一个超大的邮轮,而且这个邮轮正好挡住了这个游艇。最终渲染出来的画面是看不到游艇的,但是游艇却在pipleline中任然渲染了,造成了大量的overdraw问题,白白浪费了性能。后来加入了early-z技术,大大减少了这种无效的渲染情况。Early-Z做了什么工作呢?在应用层我们提交渲染对象数据时,根据深度信息把渲染对象从前向后的顺序排序来提交(越靠近摄像机的对象越早提交)。这样我们在处理raster之后可以在深度buffer里面读取深度值和当前渲染的对象进行测试,只有需要渲染的才进行接下来的fragment shader(图中的texture shade),这样减少了大量的overdraw的问题。
在IMR模式中会保存颜色buffer,深度buffer和模板buffer到系统内存中。在pipleline中定期的读写操作这些buffer很容易引起系统内存带宽的超负荷现象。显然对于移动设备这种带宽比较小的硬件设备性能压力就比较大。
TBR
TBR将顶点处理(vertex processing)之后的数据分成多个区块(每个tile的大小通常是16x16和32x32像素大小),然后单独去处理这些区块的数据。如图:
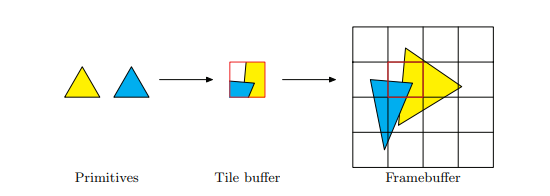
framebuffer被分成4x4个块,每个块的大小和tile buffer的大小是一样的。光栅化(raster processing)和片元处理(fragment processing)就是基于每个tile buffer区一个块一个块处理之后渲染到framebuffer的。TBR模式下将需要进行读取操作的颜色buffer,深度buffer和模板buffer存储在了GPU内存上,在处理Early Z的时候回更加高效。整个过程如下:
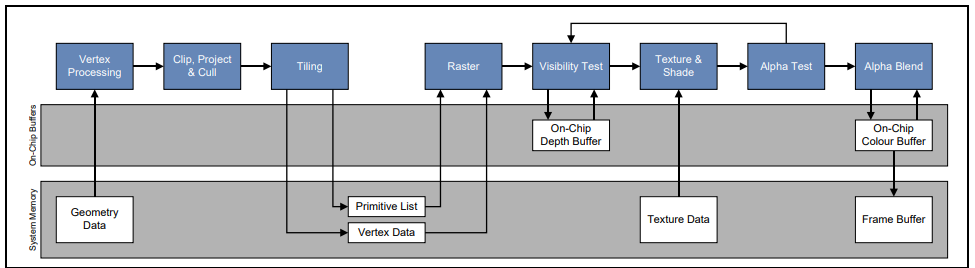
很显然TBR模式减小了pipleline的带宽,但是相对于IMR模式并没有对overdraw有更多的改进。这种模式下任然使用的和IMR模式一样的early-z的技术来检测overdraw的问题,前提同样是应用层提交的渲染对象根据深度信息进行了从前向后的排序。
TBDR
TBDR渲染架构下,GPU对应用层提交的渲染对象不会立即做顶点(vertex)和像素(fragment)处理而是先存在一个buffer里面,直到用户提交了渲染buffer或者刷新buffer命令。相当于一次处理整个场景的所有顶点数据,基于此GPU能够在fragment之前利用深度(depth)信息做HSR(hidden surface removal)优化。那些不可见的像素通过HSR优化之后全部会去掉,也避免了对这些像素的texture采样操作。这样不仅减小了对系统内存带宽的要求,也极大的减少了GPU处理tile的运算。
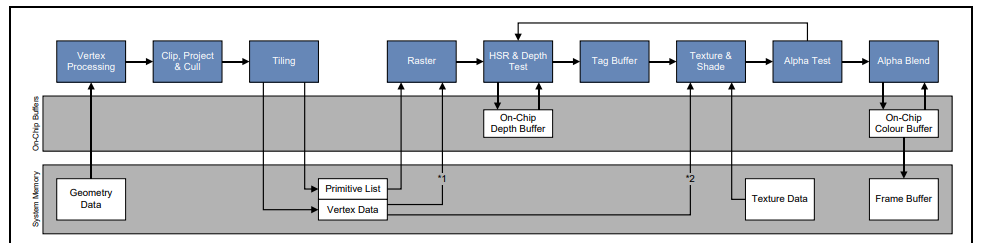
HSR处理了渲染对象之后,去除了那些不可见的像素。这保证了最终在framebuffer中的每个像素在fragment中只会处理一遍。类似IMR的通过在应用层对渲染对象根据深度值从前往后排序以便进行early-z的优化的操作者TBDR上就不需要了,反而会浪费CPU的处理时间。
不过HSR有条件限制,当开启了alpha-testing或者是fragment中使用discard指令之后,由于当前的深度信息就无法确定哪些是最终可见的像素,所以HSR处理就失效了。也就没办法解决overdraw的问题,导致了性能的压力。怎么避免这中问题发生呢?下面有几个方案:
- 先把所有的非透明的对象渲染了,然后再渲染需要discard指令操作的对象,最后渲染alpha-blended对象
- 使用alpha-blending来代替alpha-testing,在使用alpha-blending时目标的alpha值设置为0即可达到和alpha-testing相同的显示效果了
- 如果不得不使用discard操作,那么可以先用一个pass,简化这个pass的fragment shader,让这个pass把那些需要使用discard处理的对象的深度值先渲染出来。有了深度值之后再用一个pass重新渲染整个场景的对象,这个pass里面就可以正常使用HSR优化了。
通过了解上面三种渲染的架构,很显然之前提到的Unity Manual的优化tips中的 ‘Some GPU’指的就是使用了TBDR渲染架构的GPU了(PoverVR的GPU都使用了这种渲染架构,iOS使用的是PoverVR架构的GPU)。discard影响渲染性能的原因自然也明白了。
笔记的资料参考自:
END