目录
- 什么是IL2CPP
- Mono内存分配流程
- BDWGC
目录的主题之间存在相互依赖,前面三个主题是为了了解内存,第四个 Mono 内存监控是基于前三个主题的知识做的监控工具。
注:1. 本文的 Mono 内存全部指 Unity 开启 IL2CPP之后构建的手机包运行时的 Mono 内存。
2. BDWGC 指 Boehm-Demers-Weiser Garbage Collector,用在标题是全部为大写,用在文中时方便阅读我全部小写。
什么是IL2CPP
引用Unity文档中说的:
The IL2CPP (Intermediate Language To C++) scripting backend is an alternative to the Mono backend. IL2CPP provides better support for applications across a wider range of platforms. The IL2CPP backend converts MSIL (Microsoft Intermediate Language) code (for example, C# code in scripts) into C++ code, then uses the C++ code to create a native binary file (for example, .exe, .apk, or .xap) for your chosen platform.
对Unity来说,就是在项目构建时,将从C#编译后的IL代码转换为Cpp代码,用来替代Mono。下面我们用一个例子来说明下。
首先我们在C#中实现了名字为 BehaviourBase 的类,如下:
1 | |
构建iOS包之后,我们可以从Xcode工程里面找到C# IL2CPP之后的代码,如下:
1 | |
再看下追溯下MonoBehaviour的基类继承关系,最终我们可以追溯到MonoBehaviour继承自Object类:
1 | |
对应的C#中的UnityEngine的Object类:
1 | |
对比可以看到,IL2CPP之后,Object类改为继承自了RuntimeObject,那么RuntimeObject是什么呢?我们可以从IL2CPP的代码中找到定义,定义如下:
1 | |
根据继承关系我们可以得知,C#代码在Il2CPP之后,对象的内存应该是这样的:
1 | |
此外因为有了 klass / vtable 数据,对应的Cpp对象就可以获取对象的类型信息,可以实现C#的反射这类功能了。
总结下整个流程如下:

Mono内存分配流程
了解了IL2CPP的过程,我们现在回到内存部分。我们都知道C#代码运行时内存是由mono运行时托管的,开发者在创建对象的时候不需要自己显示分配内存和释放内存,使用的是GC。IL2CPP之后,内存则由il2cpp运行时托管,使用的是BoehmGC。
接下来用一个例子来演示下il2cpp的内存托管过程,首先如果在C#层调用如下代码创建一个对象:
1 | |
IL2CPP之后,我们看上面代码中的 new Node() 代码:
1 | |
可以看到 new Node 转换成了 il2cpp_codegen_objec 函数来创建,该函数最终会调用到NewAllocSpecific 再看下函数的实现:
1 | |
NewAllocSpecific 不同的分配函数最终都会调用到 Object.cpp中的内存分配宏定义(如下代码,内存分配接口收敛在这里对后面内存监控很有用), 这三个宏定义的是 bdwgc 的分配接口。到这里我们可以看到,IL2CPP对象创建的内存分配直接是被 bdwgc 接管的。bdwgc 最终在在分配的是调用系统接口分配的是系统的虚拟内存,这个后面再讲。
1 | |
总结下整个流程图如下:
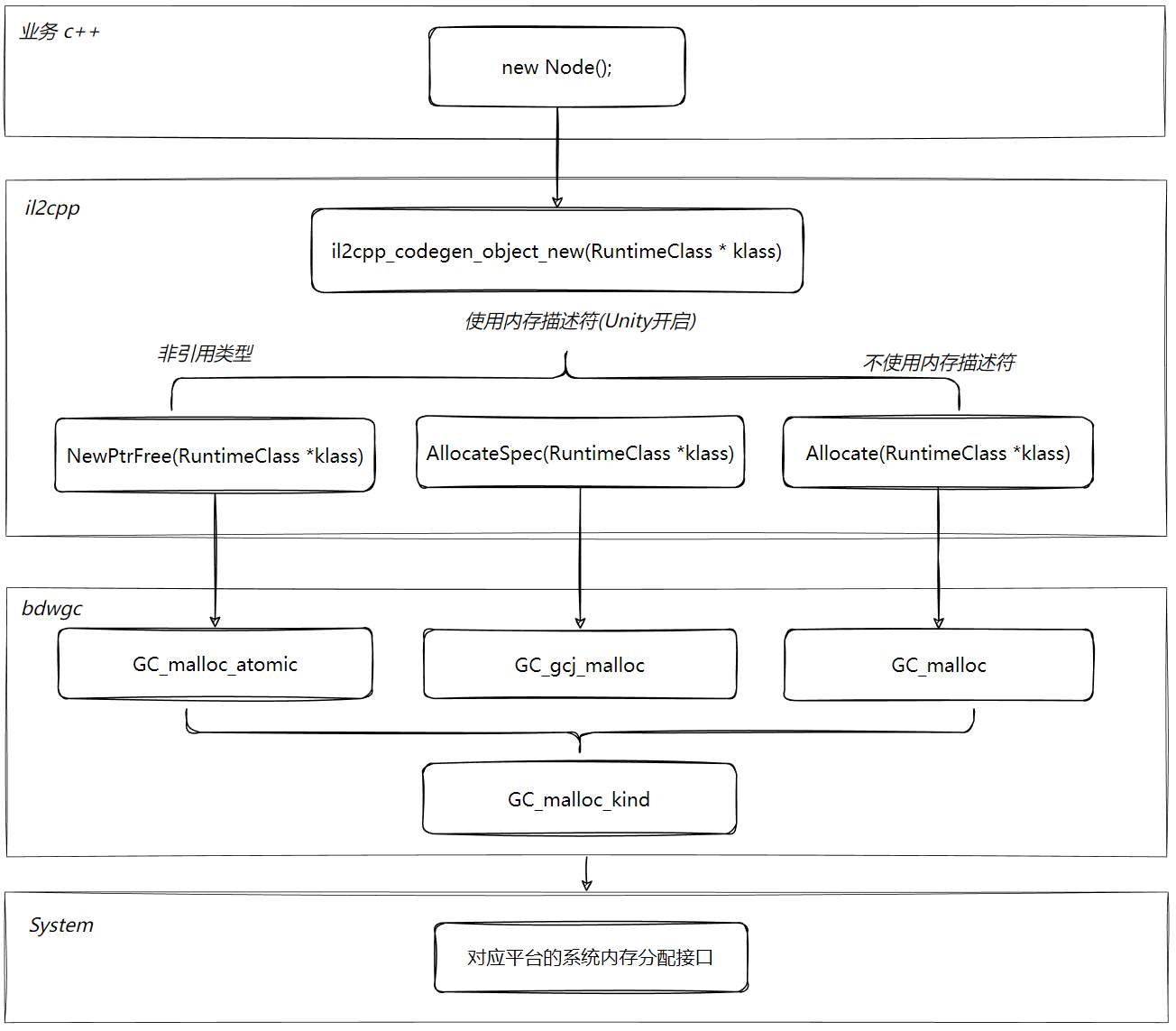
BDWGC
了解 bdwgc 的内存分配规则,我们才能知道Unity的Mono内存增长的规则。 bdwgc 指的是 Boehm-Demers-Weiser Garbage Collector,bdwgc 的作用主要是自动内存分配和释放的管理。下面讲内存的 ‘分配’ 和 ‘释放’ 两部分分别讲解下。
BDWGC 内存分配
bdwgc 的内存分配主要关注三个数据结构:
- GC_hblkfreelist : 维护了所有预分配或者可用的内存块,使用数组链表结构管理。这些内存是直接调用系统内存分配接口分配好的虚拟内存。
- ok_freelist : 维护了小块内存对象,使用数组链表结构来管理。这里维护的内存都是指向GC_hblkfreelist 的内存,这里只是做一个快速分配的管理。
- GC_obj_kinds:维护不同类型内存的数组,每个数组元素对象都包含一个ok_freelist。内存主要包括:
- NORMAL:普通的内存性,包含指针和非指针的数据,比如IL2CPP 内存分配流程图中的 GC_malloc分配的内存。
- PTRFREE:不包含指针的对象。 GC_malloc_atomic分配的内存,这些对象在垃圾回收的过程中不需要扫描,比如整形数据,元素是值类型。
看下 ok_freelist 和 GC_hblkfreelist 定义:
1 | |
下面用一个分配流程来描述下内存分配的流程,流程不是很复杂:
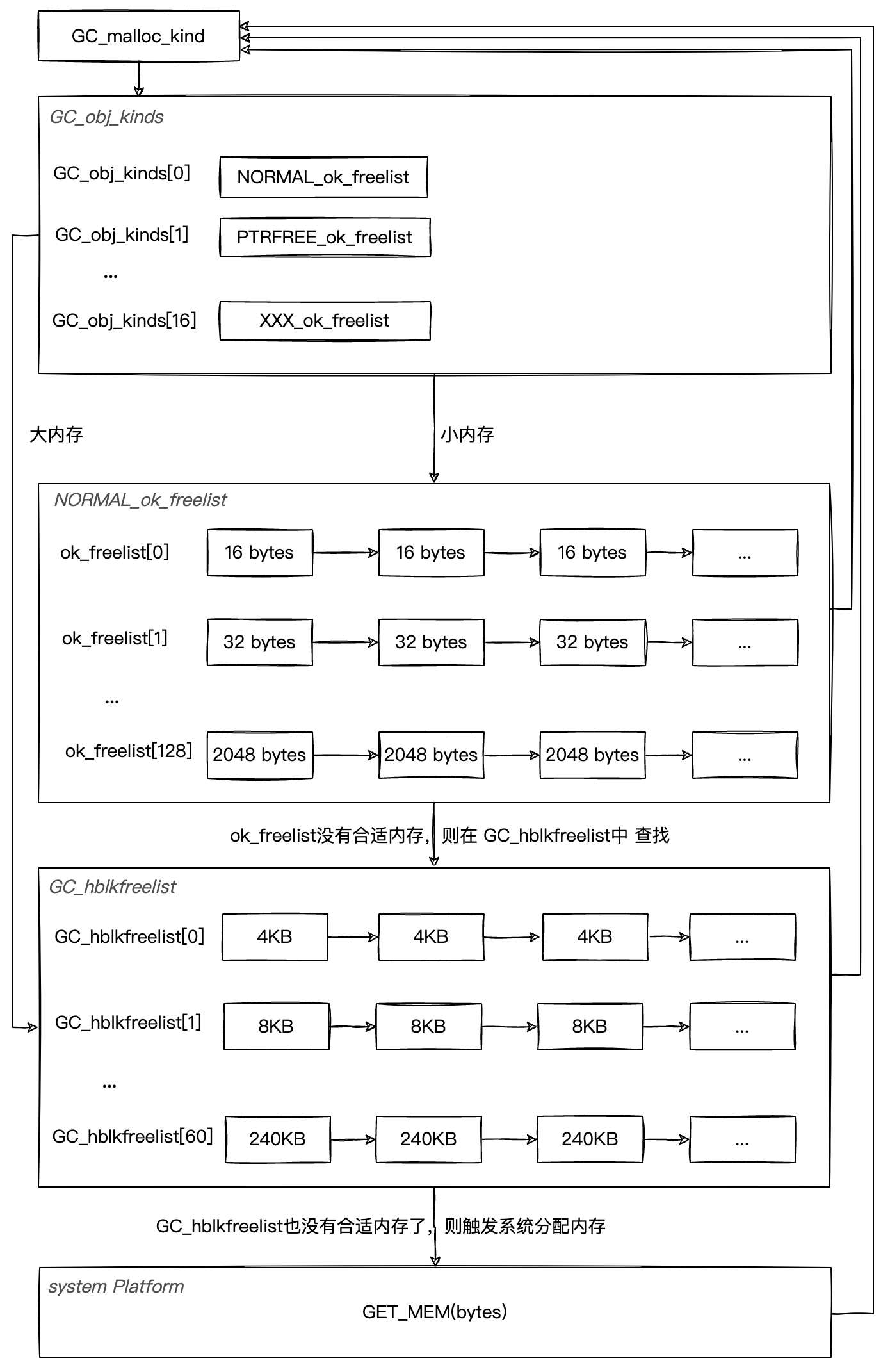
分配过程中有两点需要注意:
-
不管是 ok_freelist 还是 GC_hblkfreelist 内存都是 4 的整数倍,这个在 bdwgc 的规定,当业务创建对象分配内存的时候,如果不是 4 的整数倍,在 bdwgc 分配的时候,会先根据申请的大小向上匹配到 4 整数倍内存大小,这个大小就是 bdwgc 中实际分配的内存。
-
GC_hblkfreelist 在分配一块内存的时候会选择性拆分几块,一块内存回收的时候会尝试合并下前序和后序内存块。
基于以上两点会导致我们常说的内存碎片问题,因为实际分配的内存大部分情况下是大于申请的内存的,这样就造成多余的这部分内存用不上。而且大内存块拆分成小内存块之后,造成内存池中大内存块逐步减少,业务层程序再次分配大内存块又不得不向系统请求分配,尽管现在池子当中还有很多可用但是不连续的内存。
BDWGC 内存释放
bdwgc 内存是释放有两种方式:
- 主动调用:业务层调用 GC_gcollect(void) 函数触发GC,Unity中对应C#接口的 GC.Collect()。
- 自动调用:在请求内存分配时,如果内存池的内存不够了触发 GC。
触发GC有两种模式:增量和全量。代码里面是通过 GC_incrmental 来区分的。可以看下请求内存分配时触发GC的区别:
1 | |
上面降到的是调用层面的区别,对于增量和全量GC本身内存的区别在于,增量GC是把一次全量的GC分散到多帧执行,避免一次GC卡主太长的时间。全量GC就是执行一次,会从内存对象 GC_static_roots 做一次完成的标记扫描回收的过程。看下两者的代码区别:
1 | |
1 | |
上面提到一个概念,在回收内存之前会先遍历 节点来标记未被引用的对象。这里解释下 GC_static_roots,先看下定义:
1 | |
GC_static_roots 的构建是在库加载的时候,库加载的时候会将里面定义的全局变量和静态变量添加进来。回收时在 GC_mark_same 里,如果是全量GC,会将 GC_static_roots的所有对象添加到内存回收的标记栈里:
1 | |
到这里 bdwgc 的分配和释放规则我们已经了解。
引用: