上一篇中我们讲到了内存的Dump工具HeapExplorer,HeapExplorer可以帮助我们分析指定帧的内存情况,但是这还不够,我们还需要什么?
- 能够记录到任何一次Mono内存的分配,并且能够反定位到分配来源,类似于一个深层次并且带上行号的堆栈。可以方便的定位问题来源。
- 能够获取到每次分配的对象类型,这个便于统计我们内存分配情况,可以方便的确定优化点。
- 能够很轻松的对比多局数据,查看分配的差异。可以方便的对比不同版本相同单局的分配差异,定位内存增长部分的问题。
基于这些需求,现有的工具显然无法满足,那么我们就需要自己动手,打造一个更加 Powerful 的工具。下面介绍下针对以上需求开发的 内存追溯工具MemTracer。
MemTracer
方案思路
本文最开始的部分,我们介绍了Mono内存的分配流程,其实就是为这里做铺垫的。在Mono分配流程中分析到,Unity的Mono内存分配最终统一收敛到三个分配宏:ALLOC_PTRFREE、ALLOC_OBJECT 和 ALLOC_TYPED。
1 | |
如果我们在每次调用分配宏的时候记录下分配信息,就可以有完整的 Mono内存的分配列表了,流程是这样的(绿色部分是可以新增监听的流程):
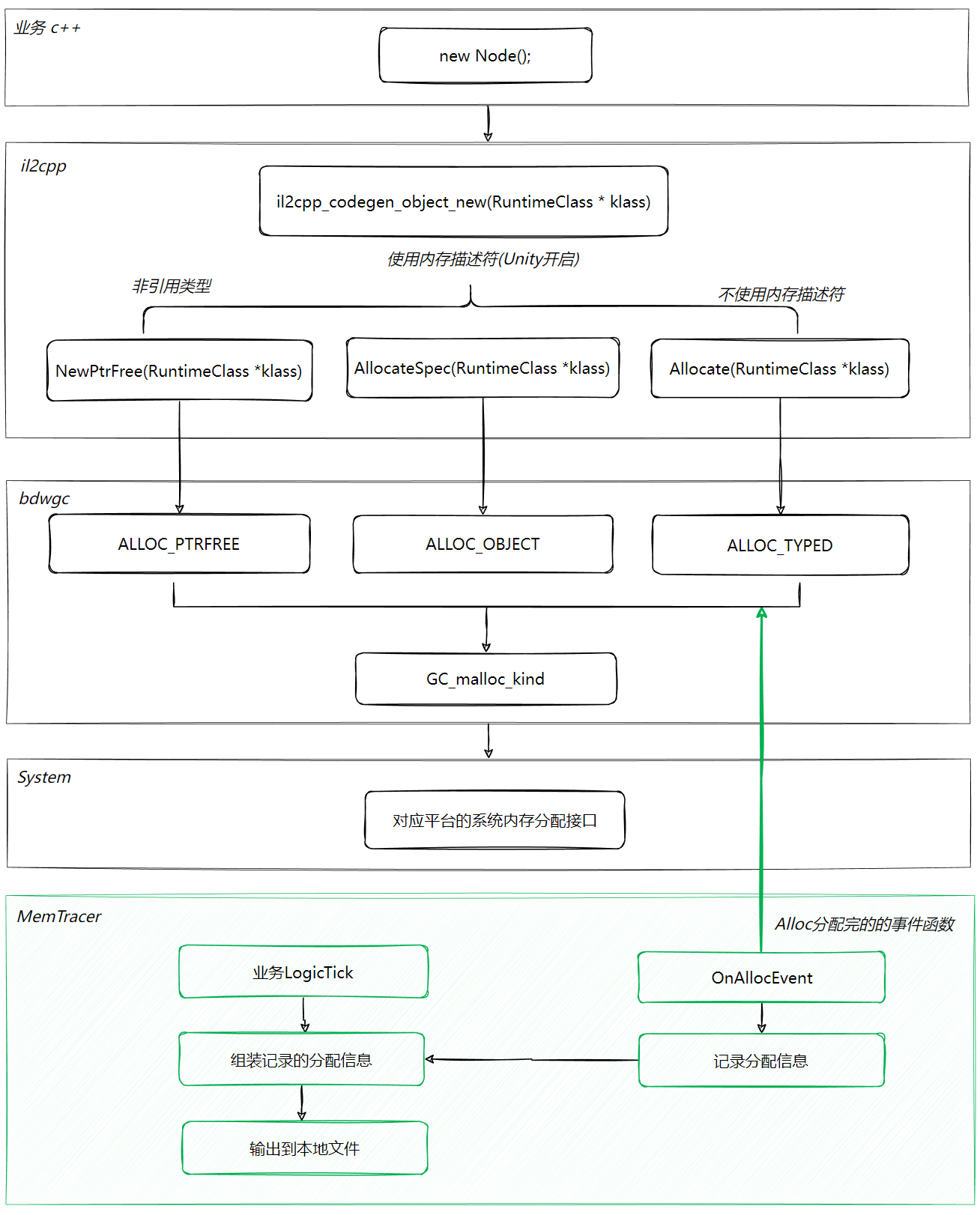
我们新增 OnAllocEvent 函数插入在 ALLOC 宏定义后面,每次 ALLOC分配完成自动调用 OnAllocEvent,我们就可以记录分配的信息了:
1 | |
另外这里的记录我们先缓存下来,然后在业务层每帧触发把缓存输出到本地文件中,把一帧的数据输出作为一次输出。
分配采样
找到了记录内存分配的时机,那么我们接下来要考虑的是具体记录什么数据。首先根据我们的需求目标,我们需要的是:类型信息、分配大小和分配堆栈,我们一个一个来看。
类型信息
类型信息其实很好获取,ALLOC的分配的对象类型都是Il2CppObject,前面已经分析了Il2CppObject结构,对象拥有类型为 Il2CppClass* 的成员变量 klass对象,klass 包含了类型名字:
1 | |
分配大小
ALLOC参数带了申请分配的大小 size,但是通过前面的 bdwgc 部分了解,申请的大小和实际的分配大小其实不一样,实际的分配大小会内存强制对齐到 4 的整数倍。这个 bdwgc 提供了一个根据对象地址获取对象内存的方法:
1 | |
分配堆栈
获取堆栈可以直接用 c++里面 execinfo 的获取堆栈方法 backtrace , 保存堆栈的做法在 bdwgc 自己的调试中也有类似的功能,并且也是用的 backtrace 方法:
1 | |
三个数据都已经准备好了,接下来看下怎么保存这些数据。
首先提出保存这些数据的要求:
- 数据尽量足够小,因为我们要保证最终的输出文件尽量小,然后数据尽量小可以保证采集内存时本身的性能开销相对较小。
- 以一帧的数据为单位,这样我们在工具显示的时候可以按照帧的趋势来显示数据,便于阅读。
基于以上两点这里确定了下使用json紧凑的格式来存储采集的内存分配数据,下面是定义的记录内存分配数据的结构,一帧数据就用一个 MonoMemorySnapshot 来保存:
1 | |
定义好了数据结构,然后直接实现采样功能即可。
地址解析
采样之后的数据是这样的:

上面截取了两帧的数据,对于这个数据我们还需要做最后一步处理,就是把记录的地址解析成真实的堆栈。因为 stacktrace 记录的是堆栈地址(stack address),如果想要转换成代码的堆栈的话,需要转换成符号地址:
1 | |
这里的 slide address 是在程序加载的时候的基准地址,对于Unity工程我们直接获取UnityFramework的slide地址即可,获取出来可以保存再内存分配数据文件的头信息中,方便后面工具解析。然后解析直接用 macOS提供的 atos 指令即可。
1 | |
这里有个点需要注意,如果项目规模比较大的情况并且内存分配的非常频繁,相应的内存分配记录文件也会比较大,记录的地址会非常多,会有几十万的地址需要解析。我们不要一个一个地址取解析,这将解析6小时+。我采取的策略是这样的:
- 因为同一个类型的对象,可能在不同地方分配,但是最终还会调用到公用的接口再触发底层分配,基于这种情况,肯定有很多记录的地址是相同的。我们可以先把记录的地址全部取出来,然后进行合并,合并之后数量会少很多。
- atos解析地址可以同时解析多个,因为本身启动atos程序就有开销,如果一次解析多个可以避免频繁启动atos。具体多少个,最好是直接用系统参数上限的个数,系统参数个数可以通过 os.sysconf(“SC_ARG_MAX”) 获取到。
- 由于解析地址本身是互相不依赖的,我们可以开启多线程解析。
采取以上步骤之后,我这边40万+的地址解析时间从原来的6小时+,减少到了60秒左右。

到此数据都准备好了。
展示工具
我们直接写个展示工具,针对展示数据的工具我们可以参考Profiler,ProfilerAnalyzer工具的布局。先细化下工具的要求:
- 能看到每帧分配的所有对象列表,每个对象类型的分配聚合在一起,能看到该对象的所有分配堆栈来源。
- 能看到整个单局分配的TOP30,这样便于全局知道我们内存是由哪些对象的分配造成膨胀的。
- 能够对比两局不同的内存采样数据,便于对比出内存差异,查出内存增长点。
基于以上需求,开发出来的工具如下:
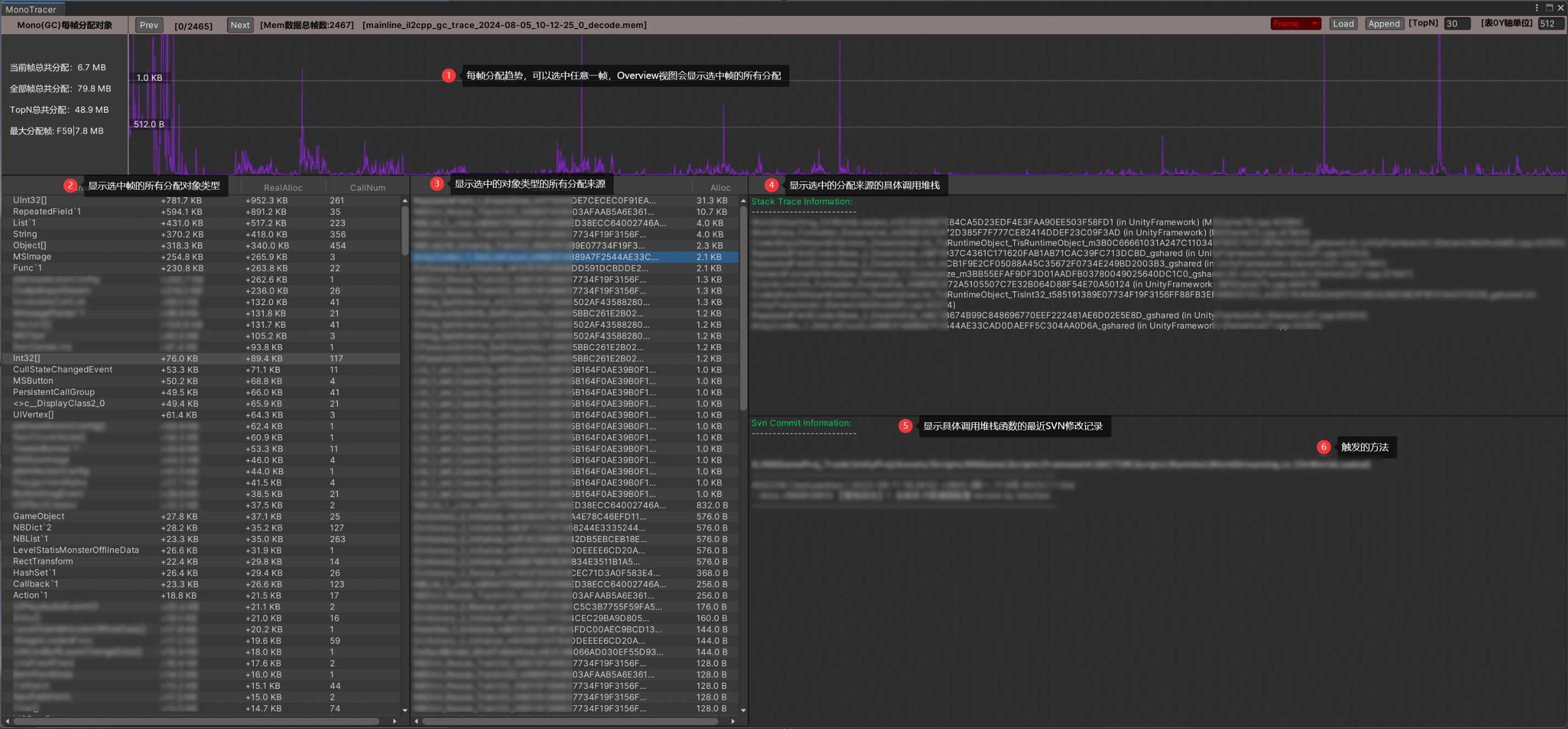
Frame视图模式
MonoTracer统计了每一帧IL2CPP对象分配,每个类型的对象分配都会记录所有分配来源,每个来源都有详细的调用堆栈,根据这个堆栈可以定位到业务层的分配调用。
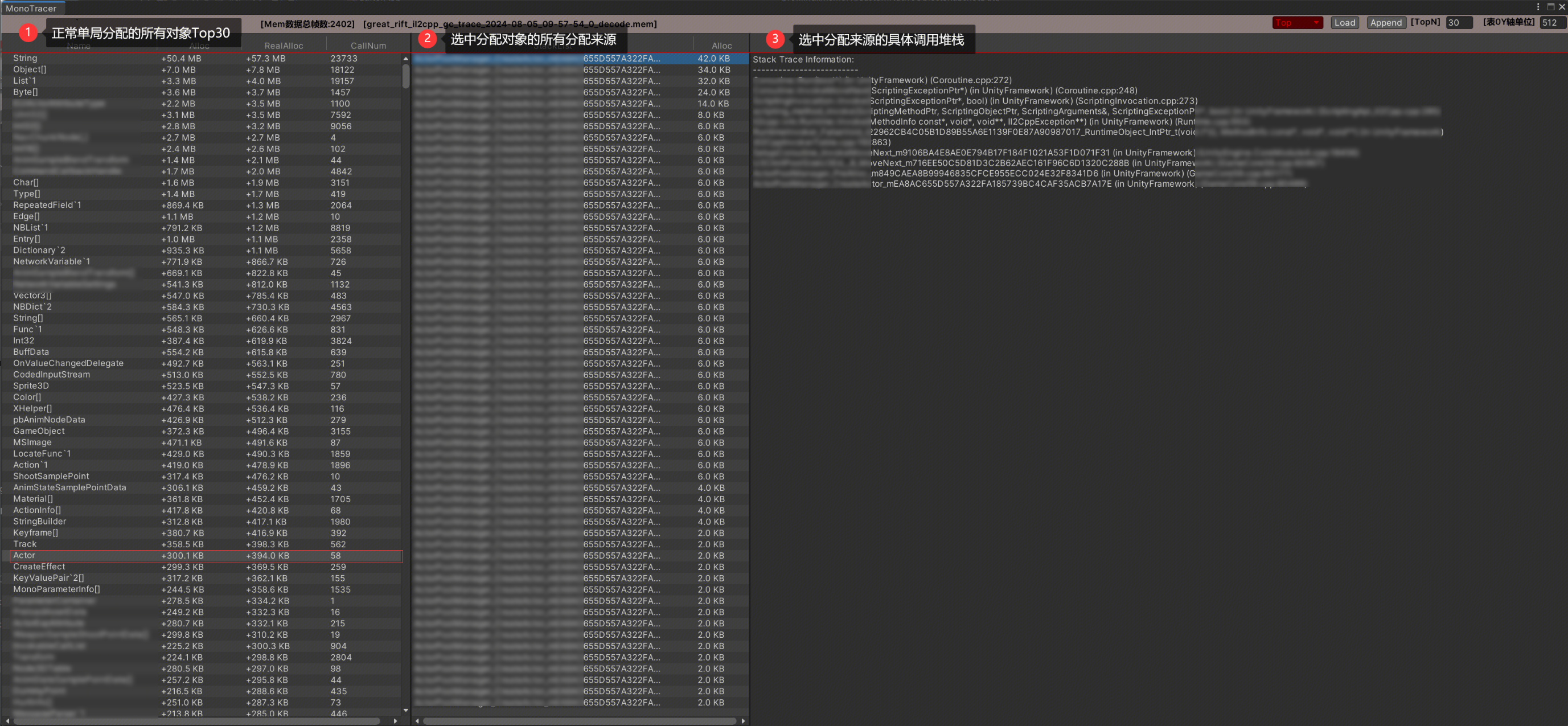
TopN视图
工具可以列出TopN的分配详情,根据这个分配排行可以来优化IL2CPP内存。
Compare视图
工具可以列出TopN的分配详情,根据这个分配排行可以来优化Mono内存。
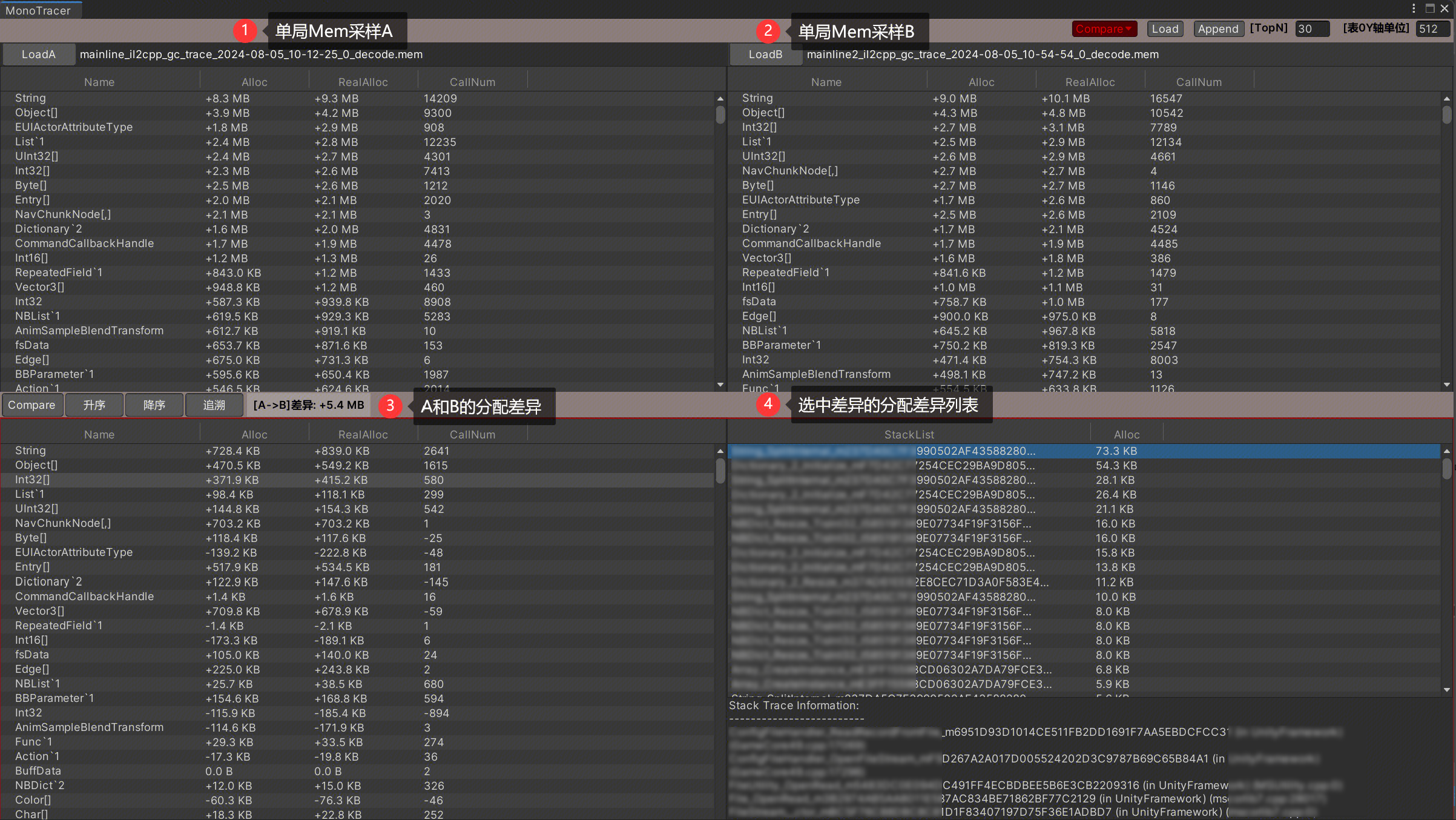
有了工具之后,就可以很方便的定位出来内存过高的来源了。