监控流程思考
随着项目的规模变大,出现性能问题的点可能会变得更加多,更加广。这种情况做性能优化时很容易让自己陷入无穷无尽的定位问题中,非常的繁琐和浪费时间。总结过往经验,很多定位问题的工作都是重复的,有个标准化,自动化的性能监控管线可以事半功倍。
性能主要指标:帧率、卡顿率、功耗、内存。
理想监控流程:
1 | |
关于数据采集方式:
- Release 包不能采集详细的业务中的性能数据(比如Unity Profiler数据),但是数据准确,没有测试环境干扰。
- Development 包能够采集详细的业务中的性能数据,但是数据不准确,有测试环境的干扰(比如自己添加了Profiler性能桩之后,因为Profiler本身的性能开销,导致整体性能会比Release包要低,上了规模的项目这种测试功能非常多,干扰的比较大)。
这里有个矛盾点:
- 数据准确的Release包不能采集详细的业务性能数据,这就导致不能做很详细的问题定位。
- 数据不准确的Development的数据能够采集到详细的业务性能数据,但是测试出来的性能又不能作为是否达标的标准。
基于此,我们可以把流程拆分开来,分别采集Release包和Development包的数据,Release包的数据用来判断性能是否达标,以及粗略分析问题,当Release包的数据不足以定位出问题的时候,再采集Development包的数据用来详细定位问题。
改进后监控流程:
1 | |
为了区分Release包的采集数据和Development包的采集数据,后面我们规定,Relase包的采集数据为 一级数据,Development包的采集数据为二级数据。
性能监控工具
对于Release包而言,我们能采集的数据比较有限,不过在有限的数据中我们尽可能的提供有价值的数据,帮助我们再Release包的性能数据中直接可以定位问题。此外数据采集本身这个行为是完全可以做成自动化的,这里的自动化包括以下流程:
1 | |
其中涉及到登录和点击UI这种自动操作可以用 GAutomator 来处理。 单局中的角色自动战斗的处理有很多方法,比如专门制作AI行为树或者使用类似对局的回放功能,只要能保证每次测试行为和环境一致即可。
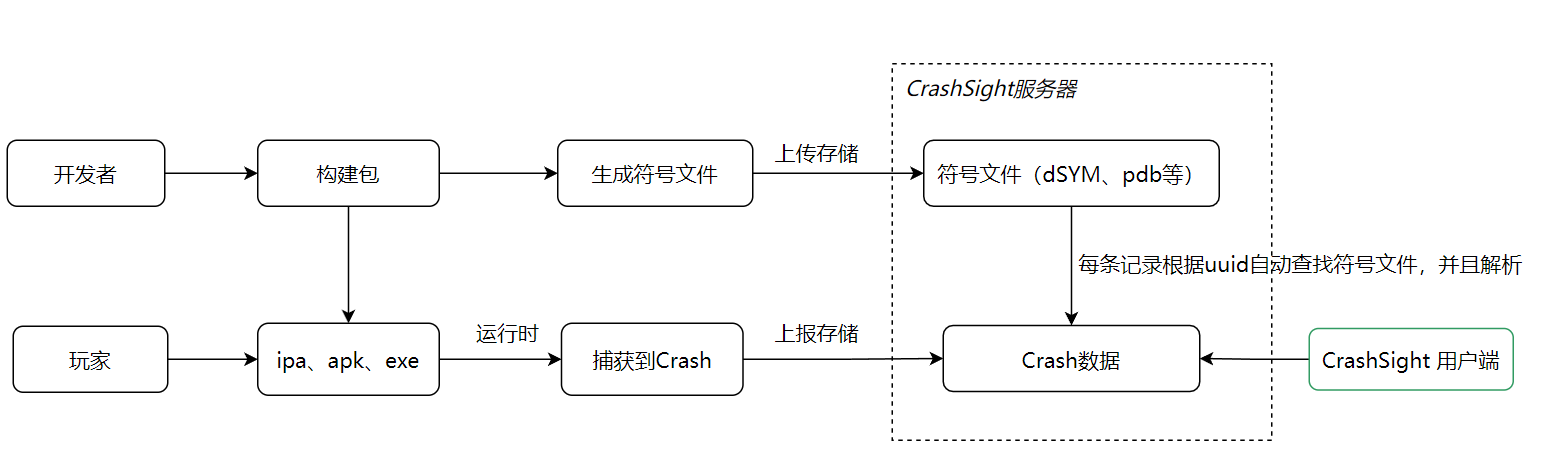
PerfDog (一级数据)
首先推荐一个第三方的性能工具就是 PerfDog,可以作为标准化数据(什么是标准化数据?标准化数据我这里指代作为性能的依据和参考),PerfDog能够采集出非常丰富的性能指标数据:帧率、卡顿情况、内存、功耗、CPU&GPU 使用信息等等。
另外PerfDog提供了开放的API,可以采集数据的同时上传自定义业务性能指标数据(当前帧创建怪物数量、创建的特效数量等等),这个对分析问题非常有帮助。当PerfDog采集出来的数据,某一帧存在严重卡顿,如果我们有采集自定义业务性能指标,那我们就可以直接根据卡顿点,关联到业务的性能指标了。举个例子:PerfDog显示采集的数据中第n帧卡顿,我们直接可以看到这一帧业务中的Actor的创建数量和总数量:
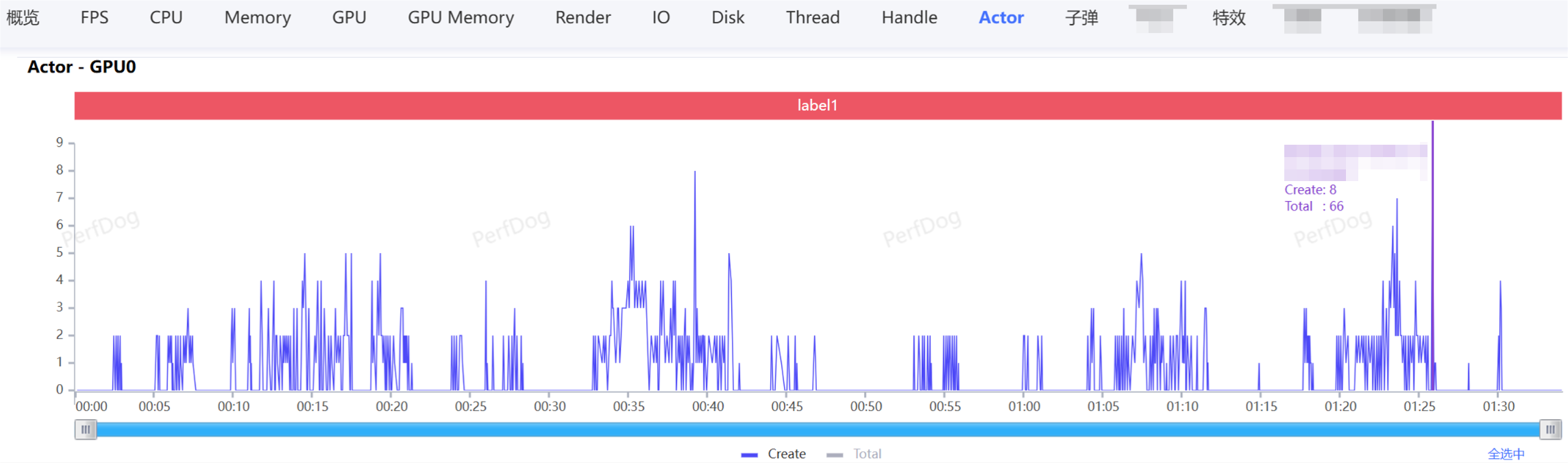
在自动化采集框架中,可以使用PerfDog提供的PerfDogService来采集,PerfDogService采集的数据在本地,可以做一些自定义行为分析,输出问题。比如,可以提取采集数据中的平均帧率内存等信息存档,并且和数据库中的基线值或者之前版本的数据自动对比输出一份最新的对比数据,来判断当前的版本的数据的问题点,大概是这样的:
‘AppName_release_b_10001’ 版本 release ‘LevelName单局’ ‘PhoneName设备’ 的 性能报告数据:
| 指标 | 当前值 | 基线值 | 变化 |
|---|---|---|---|
| AvgFPS | 57 | 60 | -5% ⚠️ |
| BigJank(/10min) | 6.8 | 6 | +13% ⚠️ |
| Peak(Memory)[MB] | 1.2GB | 1GB | +20% 🔴 |
有了这个对比数据之后,我们知道此单局在对应设备上相比于基线值哪些数据不合格,不合格之后我们需要进一步分析原因。
模块耗时 (一级数据)
模块耗时这个也是为了在一级数据中采集更多信息来帮助分析问题的,主要是帮助分析CPU侧耗时开销。一级数据中我们主要对关键模块的耗时进行统计(统计的过多会影响性能)。
这里解释下我指代的关键模块,比如引擎相关的 Rendering.RenderFrame、Rendering.Submit、EventSystem.RaycastAll等,业务层的 子弹模块根部的Tick、技能Timeline模块根部Tick、加载模块的根据Tick等,耗时我们可以通过 Time.realtimeSinceStartup 的时间,然后记录函数调用开始和结束的时间差来统计,引擎里面的模块函数统计可以通过 PlayerLoopSystem 处理,可以在PlayerLoopSystem的subSystemList中插入自己的统计updateDelegate,具体的做法可以参考这篇文档。有了这些数据,我们可以通过和基准数据对比,看哪部分上涨了,就可以分析出来CPU耗时上涨的大概原因了。形式大概如下:
‘AppName_release_b_10001’ 版本 release ‘LevelName单局’ ‘PhoneName设备’ 的模块耗时数据:
1 | |
数据采集之后可以自动分析数据生成如上数据,这样可以看出 UIModule.Tick 消耗明显提高了,到这里我们可以从两个方向可以继续查这个问题,第一个最直接的直接找业务同学问这里是否有UI内容的增加,有内容增加的话,可以直接去分析具体增加的内容。第二可以直接采集二级数据来详细分析耗时新增具体是哪里引起来反推具体的内容。
内存概要(一级数据)
Unity项目中的内存主要包括以下几部分:
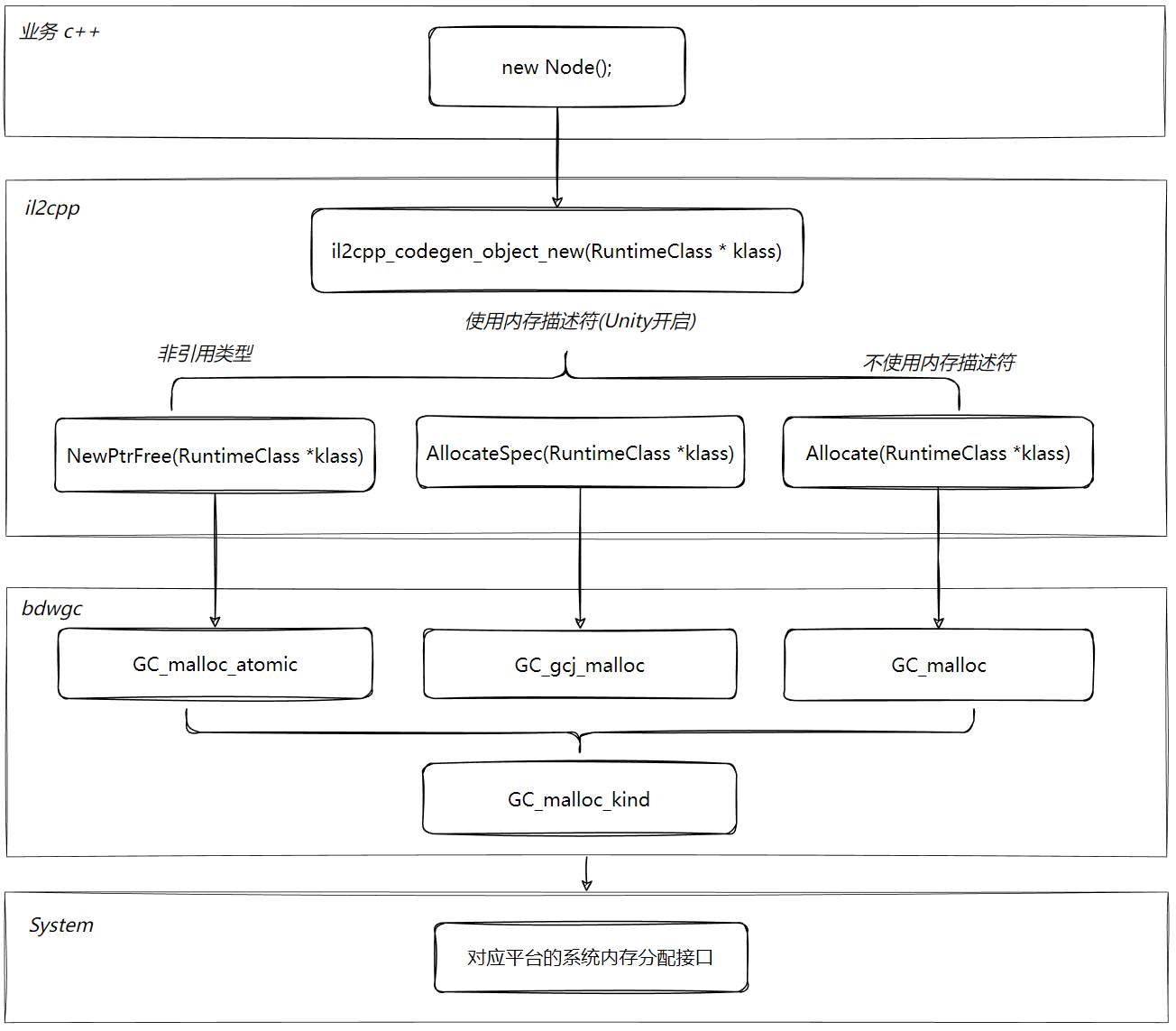
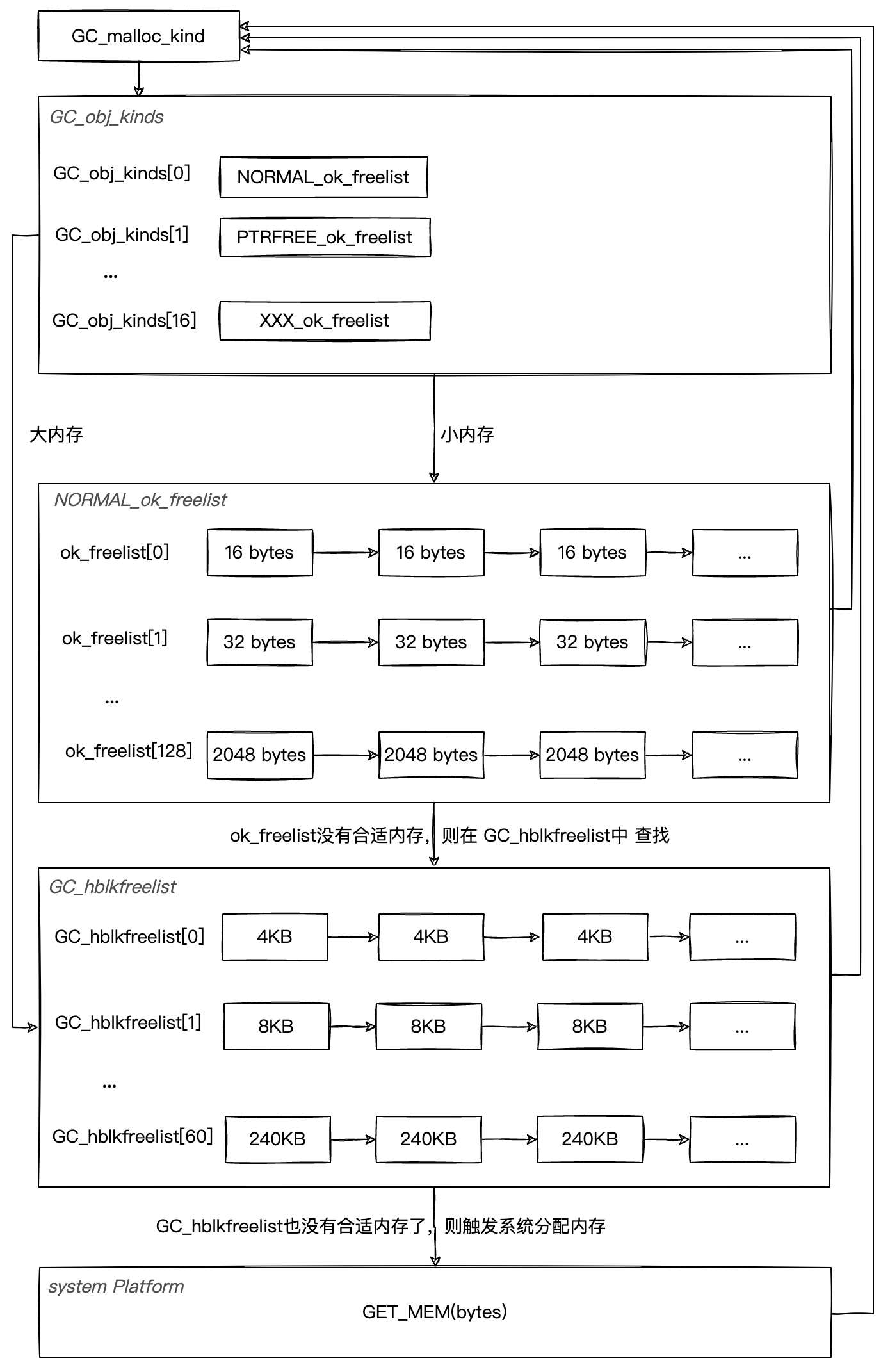
- Managed memory (托管内存):这部分内存是我们业务层C#代码使用的内存,IL2CPP之后虽然是C++代码,但是这部分内存任然是被托管的,被托管的内存自动分配和自动释放的。
- Native memory:引擎C++使用的内存,包括加载assets的内存。
- C# unmanaged memory:这部分内存是C#代码的,但是又是非托管的。比如使用UnsafeUtility.Malloc,UnsafeUtility.Free分配和释放的内存。这个目前我经历的项目都用到的比较少,这里不作为重点考虑。
- Lua memory:现在很多项目都是使用Lua来实现UI系统模块的,甚至是战斗模块的。所以Lua内存占比还挺高的,在我们项目Lua内存峰值曾经达到120MB,需要重点关注。
前面提到的PerfDog能够统计到每帧的总内存使用情况,此外我们可以统计出来各类型的内存数据。Unity引擎提供了获取Mono内存和总内存的API:
1 | |
此外Lua内存的获取语言本身提供了API:
1 | |
有了这些API同样,我们可以每帧统计这些数据来做自动分析对比。类似模块耗时一样,我们做一个内存分项和基准值或者历史版本值对比来发现问题。形式大概如下:
‘AppName_release_b_10001’ 版本 release ‘LevelName单局’ ‘PhoneName设备’ 的内存数据:
1 | |
这里对比是对比的一场单局的内存均值,可以自己拓展细分项内存的指标,如果有引擎代码的话可以把 Texture2D内存这种比较重量级的都统计出来,可以方便通过一级数据就可以确定大概问题了。
UnityProfiler数据(二级数据)
针对帧率,卡顿率问题
正如监控流程中描述的一样,如果一级数据不能够定位出问题,那就需要继续采集二级数据来详细分析。针对帧率和卡顿率问题,我们可以采集UnityProfiler数据来做分析,Profiler本身只有少量的函数采集,我们可以把自己的耗时模块函数都添加上性能桩:
1 | |
这里有一点需要注意,性能桩越多,Profiler本身对性能的影响就越大,也就是数据越失。不过我们已经通过一级数据定位到大概位置,这里Profiler采集的二级数据只作为查问题的数据,建议桩能够覆盖全项目的耗时函数,性能桩的API只会在Development包里面生效,Release包不会编译进库。
因为是自动化采集的,采集Profiler数据通过Unity的脚本化接口来采集而不是真机连接Editor的Profiler,这个Unity本身提供了API:
1 | |
采集数据之后我们可以用Profiler + Profiler Analyzer来分析,主要还是Profiler Analyzer工具,此工具可以统计单个性能桩在整个数据中的平均消耗等数据,会把TopN的峰值消耗筛选出来,并且还可以用来比较两个Profiler数据,非常的方便:
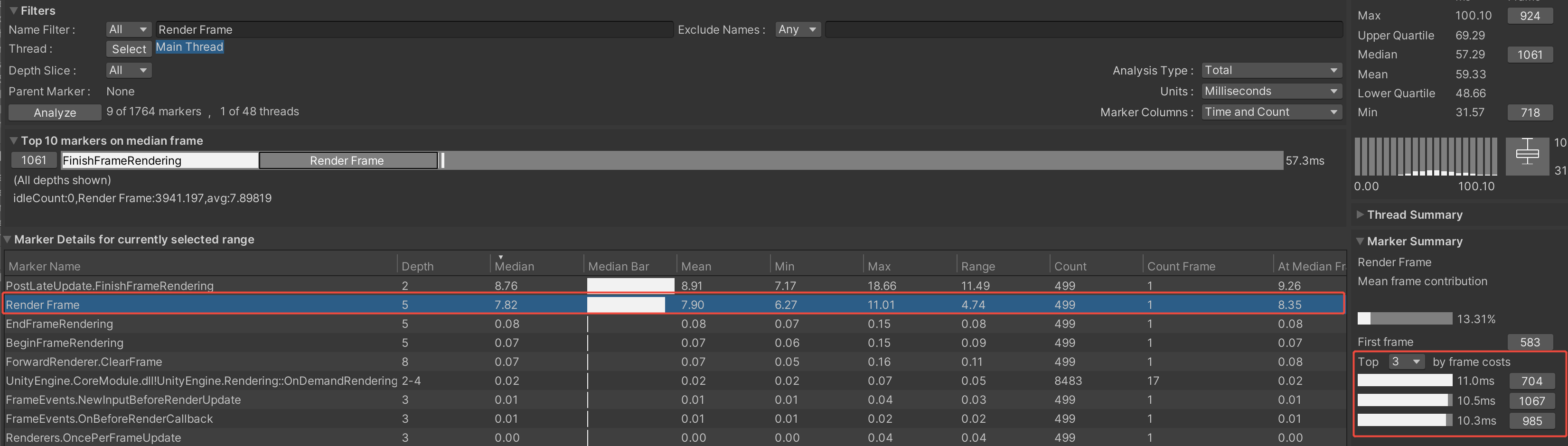
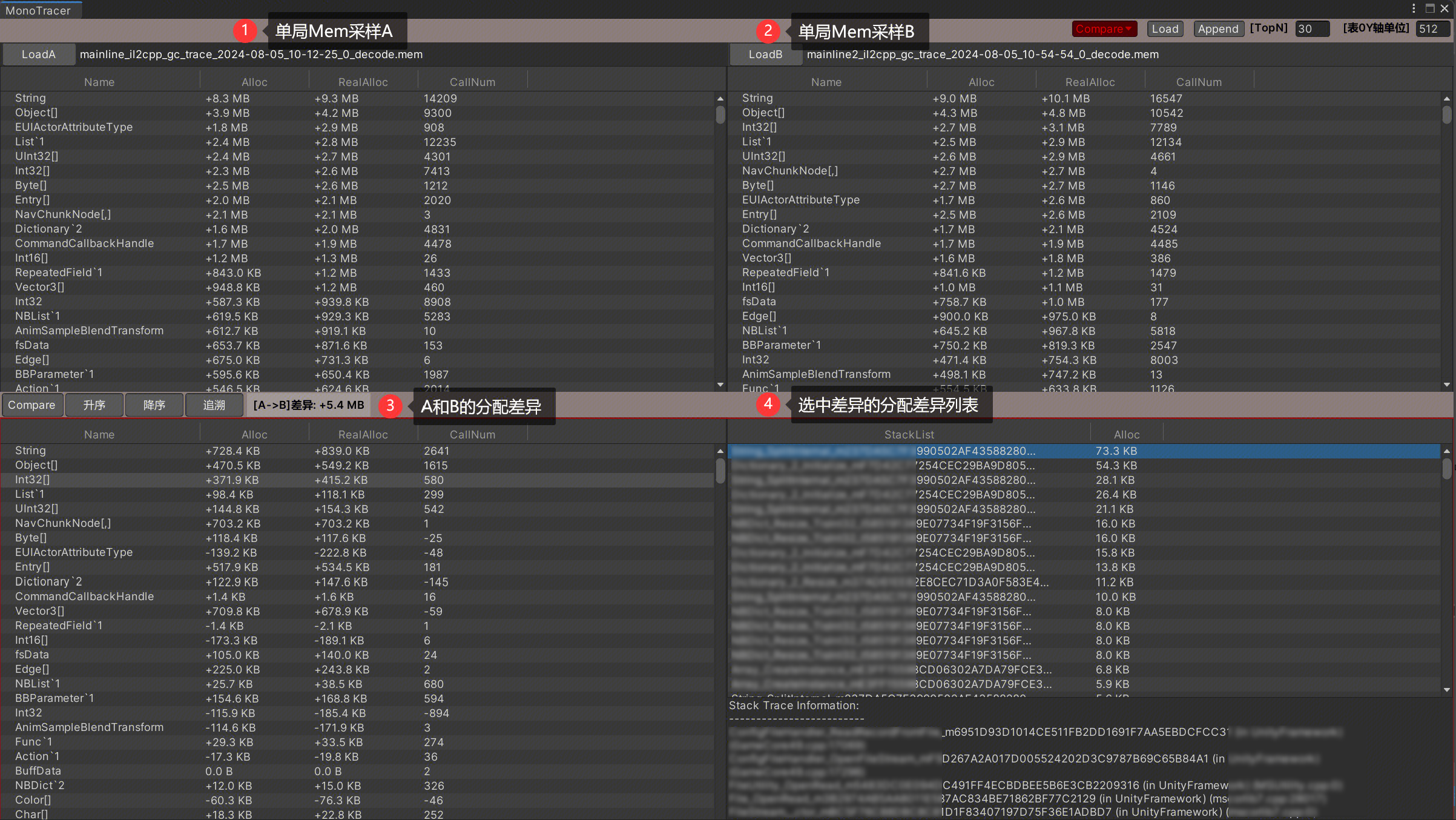
有自定义性能桩的话可以一步一步追溯到具体的消耗的函数。另外我们可以对这个数据也做自动化分析处理,我们可以自己尝试解析Profiler数据来提取卡顿帧,以及版本对比提取耗时超出的性能桩数据,具体可以参考ProfilerAnalyzer的处理方法。
Dump&Trace内存数据(二级数据)
内存
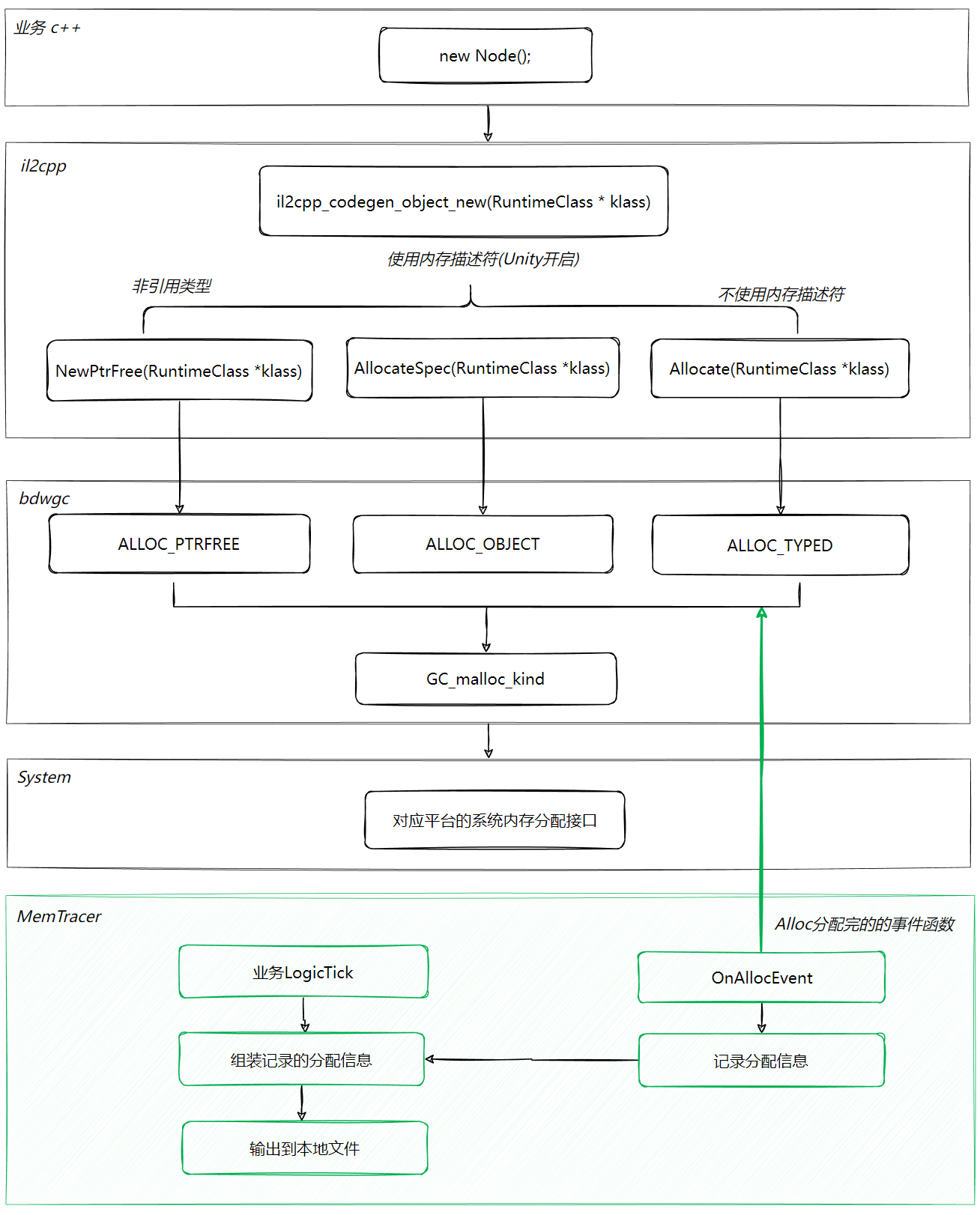
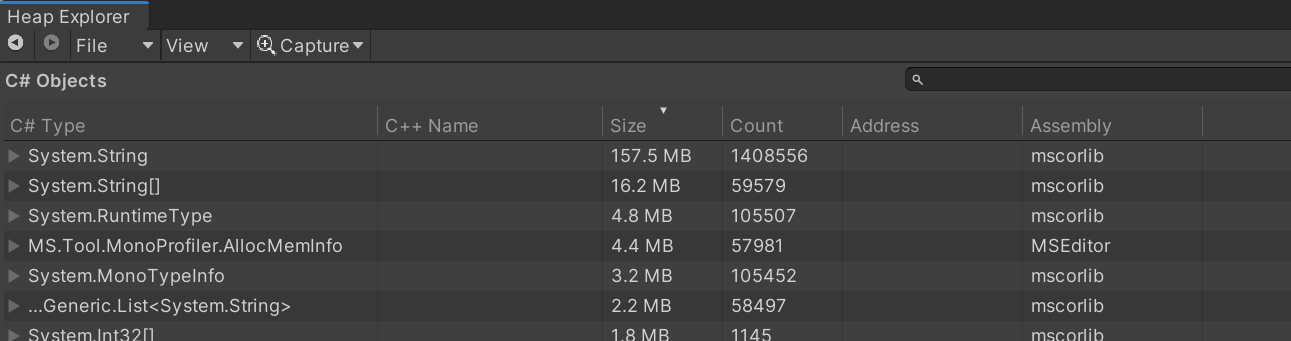
Dump内存我用的是HeapExplorer,因为MemoryProfiler对Unity2019版本有些不兼容。HeapExplorer之前我具体介绍过,具体可以看这篇[Unity内存(二)内存快照]。简单来说就是查看当前帧正在利用的这些内存由哪些对象,可以定位出那些长时间不释放,或者由于BUG没有释放的内存。
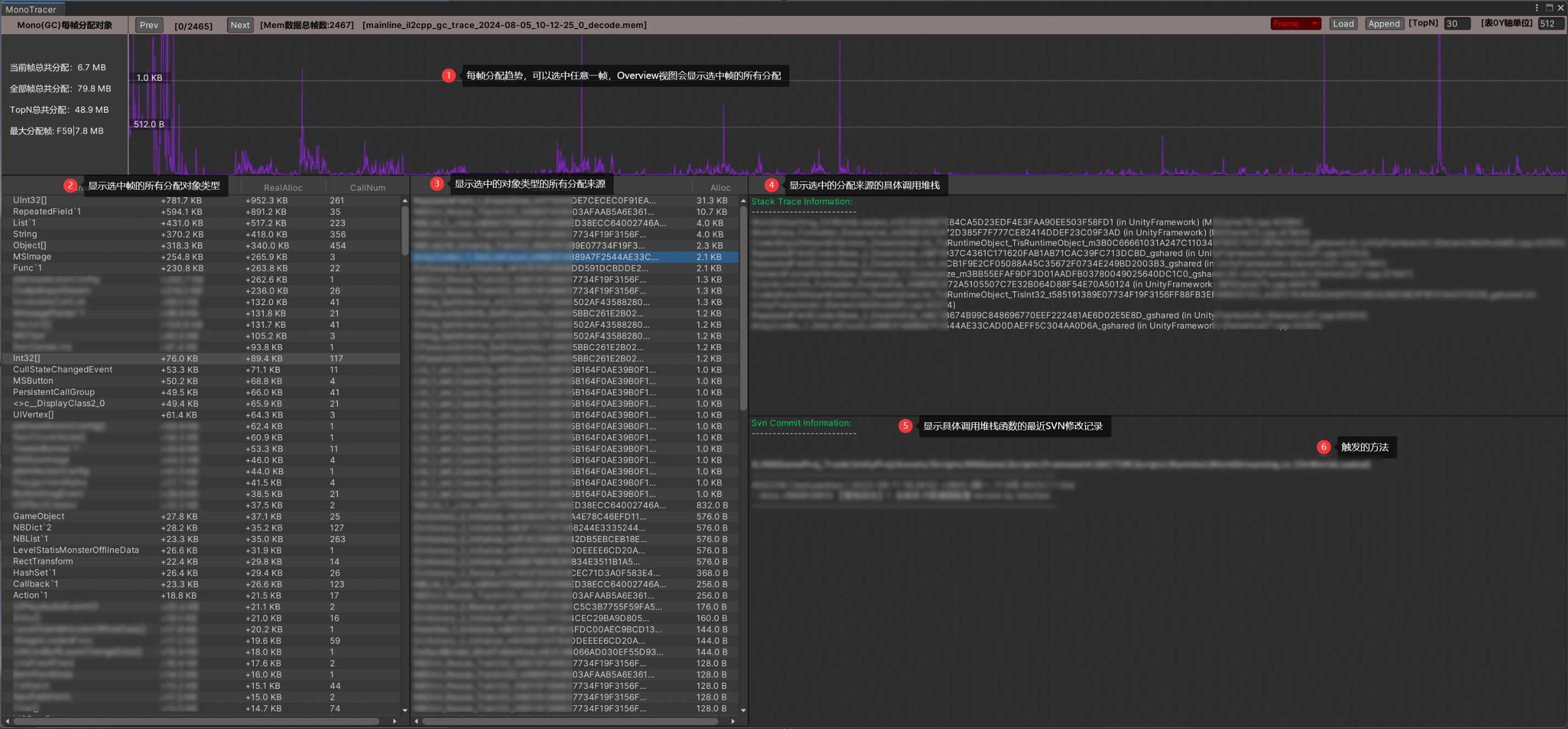
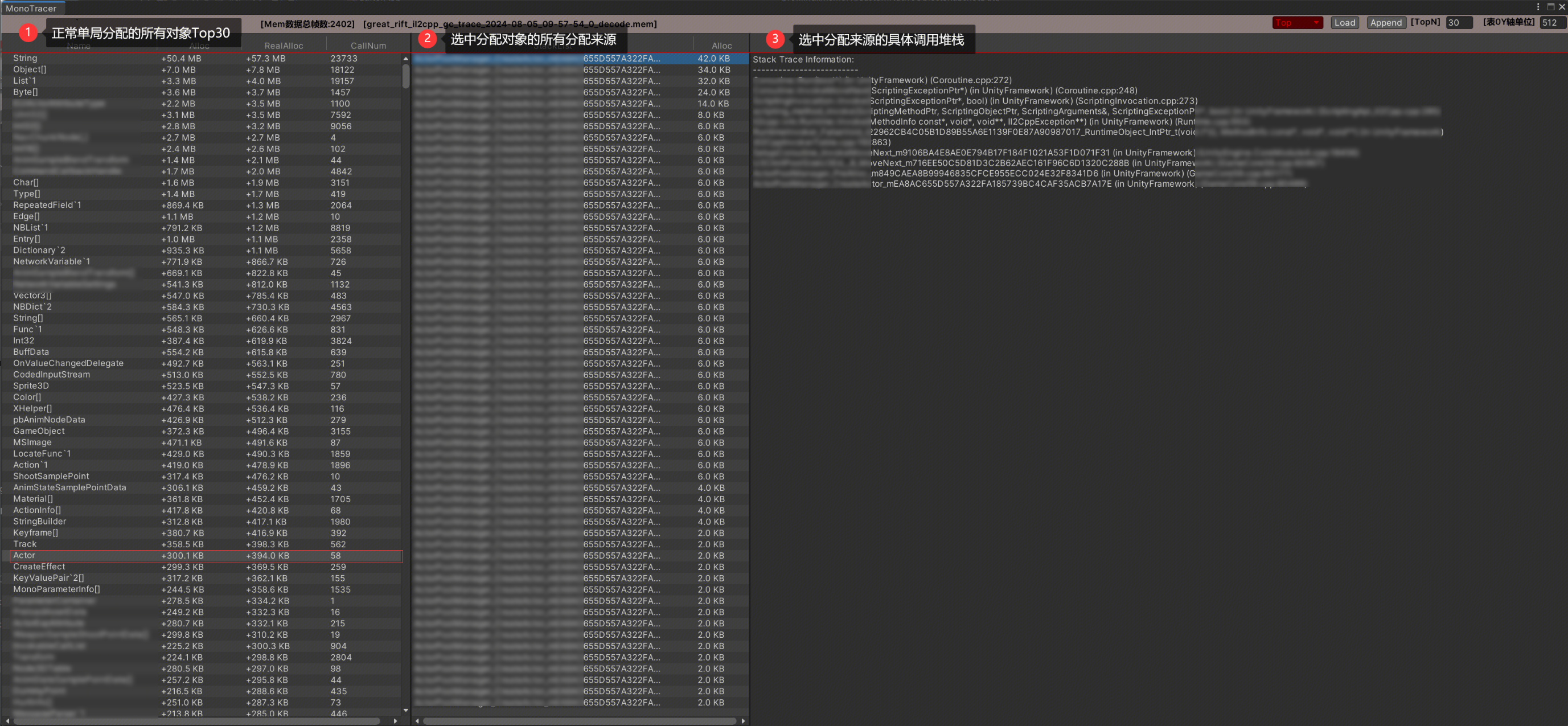
内存Trace我是自己做的工具,详细的做法和功能可以看这篇[Unity内存(三)内存追溯]。Trace解决的是Reserved内存过大的问题,方式是记录每次分配来源,因为有些对象确实释放了,但是因为过程中频繁分配,并且大量分配,我们需要追溯到这些分配才能定位到具体的分配代码位置。
资源加载数据(二级数据)
内存
资源加载是一个纯逻辑层可以做的数据统计,但是这个又很关键,因为资源加载往上涉及到具体的业务,往下涉及到系统的IO和引擎内存。如果能够监控住资源加载,自动检测到变化异常,对提早发现那些场景资源量过大,同时实例化对象过多,甚至是功耗过大这种问题非常有帮助。
资源加载可以从GameObject.Instantiate、AB的LoadAsset、AB加载等来监控。指标上可以是每帧加载的数量、加载的耗时、当前已经加载的总数量来统计。因为和具体项目相关性太高了,这里不做详细的讨论,每个项目资源处理的方式可能不尽相同。
完善监控流程
到此,我认为的性能监控的主要涉及到的性能指标都讲了对应的性能监控工具以及简单介绍了分析方法,当然根据自己的项目可以再做更加详细的监控指标,比如渲染相关的场景中对象DrawCall次数,ParticleSystem运行的数量,逻辑相关的还可以用SimplePerf等等。下面完善一个相对正式的性能监控流程:
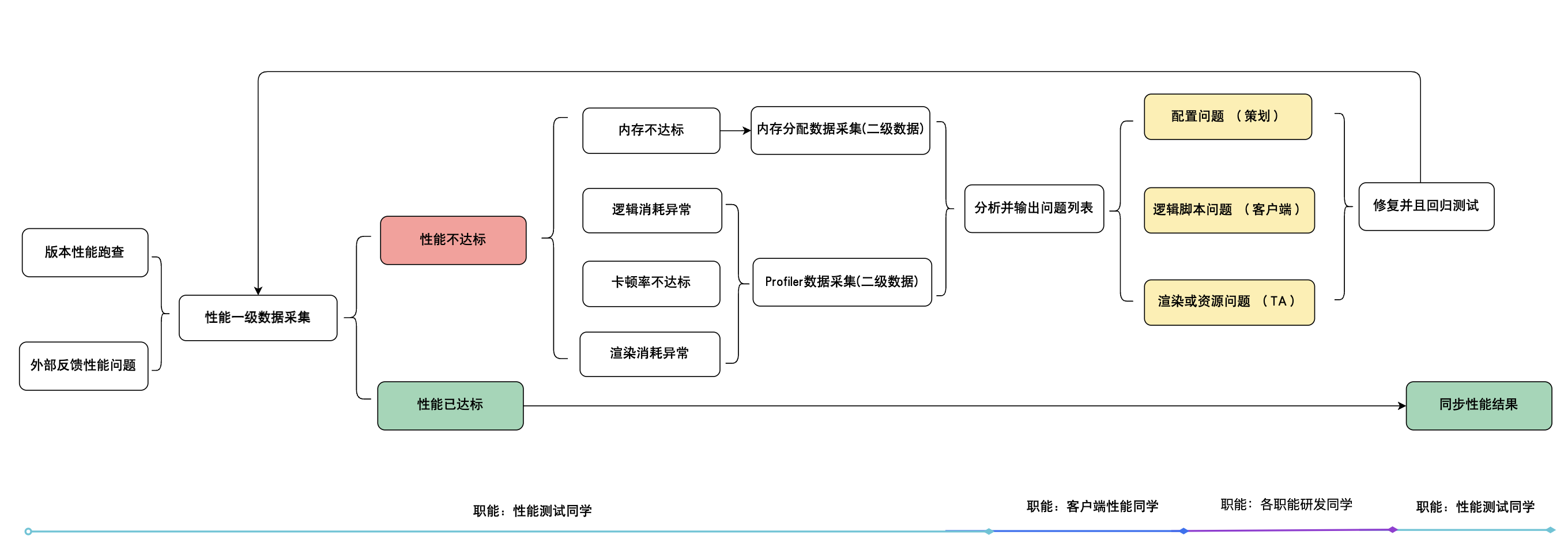
此外,针对上面提到的模块耗时问题,这里多提一点。在我经历的项目中,经历过两种性能优化的工作流:
a. 性能的同学定位出具体的问题,找到具体的原因以及修复方式,然后再找出问题的代码的作者或者功能负责同学处理。
- 优势:
- 这种模式模式的好处就是,业务的同学不需要关注性能,出了问题会有专门的人帮自己分析问题,自己只需要修改问题就行,减少了业务同学的压力。
- 弊端:
- 就是性能同学需要对业务足够熟悉,因为有些性能问题不是单个函数造成的,而是一个具体的功能逻辑并发造成的普遍消耗上涨,性能同学的压力就比较大。
- 由于业务同学不会接触到性能的具体事物中,平时做业务时对性能敏感度比较低,输出的业务性能出现问题的可能性相对较大。
- 由于业务同学不需要关注性能,这里有个冲突点就是,当性能同学查出具体问题的时候,往往是在版本中期之后甚至是版本后期,此时派单到业务同学这里处理,业务同学这里会存在业务需求和性能需求冲突的问题,这里就需要有专业的PM来管理这里的需求关系,不然比较容易造成业务同学这里需求优先级不明确,甚至没有预留处理性能需求时间(这个也比较难预估时间),造成性能问题难以推进的问题。
b. 性能同学只负责完善数据采集,完善问题分析工作管线以及引擎侧性能。具体模块的性能给到具体业务模块的负责人,那么模块负责人就是自己模块性能的owner,性能好坏就是你的KPI。当版本模块耗时统计数据出来之后,每个模块负责人关注自己模块是否存在性能问题,需要做二级数据分析的,自己分析,PM或者技术负责人整合推动性能进度,定期同步当前性能情况和问题处理情况。
- 优势:
- 业务同学自己关注自己模块的性能,有助于业务同学提升性能敏感度,对项目整体的性能意识提高非常有帮助。
- 解放了性能同学分析具体问题的时间,可以更加专注优化整个性能管线,建立更加完善便利的自动化管线和分析工具。
- 避免性能同学需要熟悉具体的业务逻辑来帮助分析数据的问题,以及在熟悉具体的业务时和大量业务同学沟通的时间损耗,也减少了性能需要需求推进的难度。
- 弊端:
- 业务同学自己分析性能问题从经验和熟练度上需要时间积累,这里会有些损耗。
这里列出这两种优化的工作流的在规模较大的项目处理性能问题时,用模块耗时这种明确问题职责式的性能处理方法有优势,也想表达从这两种工作流中我理解到光有技术是不够的,怎么用好这个技术来解决问题才是关键。
引用:
Optimize your game performance for mobile, XR, and the web in Unity